Edge computing, wherein the provision of services and processing of data occur at the “edge” of a local network rather than through a cloud provider, has prompted a shift away from cloud computing in recent years. Information security and privacy, reduced latency, and an increase in intelligent applications are primary reasons driving the adoption of edge devices for infrastructure and enterprise, as well as consumer market verticals. Based on a study by Allied Market Research, the global edge computing market is projected to grow by almost 33% yearly.
Consumers do recognize the benefits offered by voice-enabled products. Voice interfaces appeal to those with convenience in mind, as well as those who are reticent to continue using touch-based controls due to hygiene concerns. However, wider adoption of these products is hampered by concerns about privacy, accuracy, and the ability of devices to recognize various accents or dialects.
With 75% of consumers surveyed in 2020 reporting some level of concern — 30% responding that they are “very concerned” — unease regarding user privacy is one of the major barriers to overcome. Language coverage is also a major user concern about conventional voice recognition systems, as well as frustration resulting from inaccurate recognition across different accents.
Arm Cortex-M series processors, designed with energy efficiency and low cost in mind, provide an ideal target platform for building voice control functionality into a wide range of embedded applications, from fitness trackers to battery-powered remote controls to home appliances. With these processors, product makers have an opportunity to provide voice-enabled products that are cost-effective and efficient, but it is increasingly important to provide solutions that address the lack of confidence in the areas outlined above.
Fluent.ai and DSP Concepts: Bringing Accurate, Noise-Robust Voice Recognition to the Edge on Arm-Based Platforms
Fluent.ai technology offers benefits not seen in cloud-based and other edge-based voice recognition providers.
Amid noisy environments, this solution overcomes noise from sources such as washing machines, HVAC, and fan hoods, delivering an extremely high rate of accuracy in recognizing wake words and commands in the near field (within 1 m). With multi-microphone designs utilizing Fluent.ai technology, similar performance can be obtained with far-field (3+ m).

TalkTo combines advanced signal processing techniques to deliver clean audio signals to voice assistants and speech recognition engines. TalkTo features can be tailored to meet a wide range of design requirements, scaling to fit platform limitations, acoustic environment, and use case. Used in combination with the Fluent.ai Wakeword and Fluent.ai “Air” speech-to-intent recognition model, this audio front end (AFE) provides an accurate and reliable voice interface with robust noise rejection.
![]()
Audio Weaver is a low-code / no-code audio development platform that accelerates and simplifies the processes of building and developing voice-enabled products. With Audio Weaver, teams can develop platform-agnostic designs that can be deployed to various target products with no redesign needed. This allows for rapid testing and iteration of audio designs without hardware, enabling developers to work in parallel to independently implement features for later, seamless inclusion in the final product design.
![]()
Fluent.ai Air provides accurate and noise robust speech recognition that supports multiple different accents and languages in a single system, addressing the consumer concerns about accent-sensitive systems without the need to make concessions in memory size or CPU clock speed. Due to the linguistic flexibility of this system, manufacturers can utilize a cost-effective processor and deploy a single SKU across a wide geographic market, saving on both cost and development/localization time.
Privacy is another user concern that this solution addresses. Due to their operation either offline or at the periphery of the network, edge-based voice-enabled devices operate as contained systems that do not require transmission to and reception from the cloud. This method of local operation significantly decreases latency in recognizing and processing commands, allowing for a seamless user experience that is private by design.
The combination of software solutions provided by Fluent.ai and DSP Concepts can be deployed to any Arm Cortex series processor and are well suited for the small-footprint Cortex-M series.
How Does it Work?
Conventional automatic speech recognition (ASR) models operate by converting speech to text, then utilizing cloud-based natural language processing in the target language to determine the user’s intent (Figure 1). This approach requires the transmission of large amounts of data and the use of large amounts of computing power. Additionally, this approach to ASR incurs enough latency to interrupt what would ideally be a natural interaction.
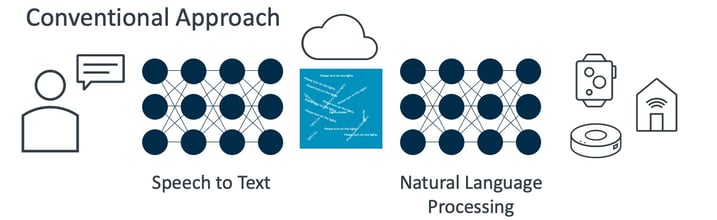
Fluent.ai has developed a model that seeks to remedy the issues of computing footprint, reliability, and latency that are present in traditional models. Employing unique neural network algorithms, Fluent.ai’s speech-to-intent approach is language and accent-agnostic, determining the intended action based on the incoming speech with no need to convert speech to text or utilize cloud-based natural language processing (Figure 2). This model operates at the edge, with no need for internet connectivity and no reliance on third-party language processing.
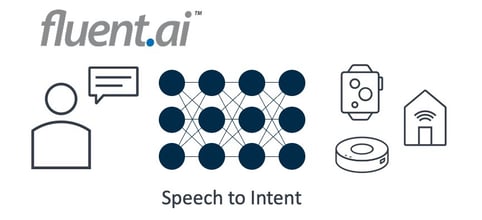
The combination of Fluent.ai Wakeword and Fluent.ai Air, DSP Concepts Audio Weaver, and DSP Concepts TalkTo comprises a noise-robust and multilingual voice user interface (VUI) that is an ideal solution for manufacturers of white goods and other products.
A demonstration of this technology can be seen in this video of Fluent.ai Air and DSP Concepts TalkTo in action, with a wake word and flexible command set.
Where Are We Going from Here?
The next stage of VUIs has the potential to offer “better than human” understanding of commands, cutting through environmental noise to determine the user’s intent regardless of language or accent, and deliver a customized and frustration-free user experience.
With the flexibility of the Audio Weaver Platform, DSP Concepts provides developers an end-to-end solution for programming, real-time debugging, and tuning, reducing the development overhead required to create edge-based VUIs for various use cases.
Fluent.ai is partnered with DSP Concepts to bring this flexibility and ease to developers of voice-enabled solutions on Arm Cortex-M4 and -M7 based devices.
To learn more, please visit the Fluent.ai Reference Design page at DSP Concepts.